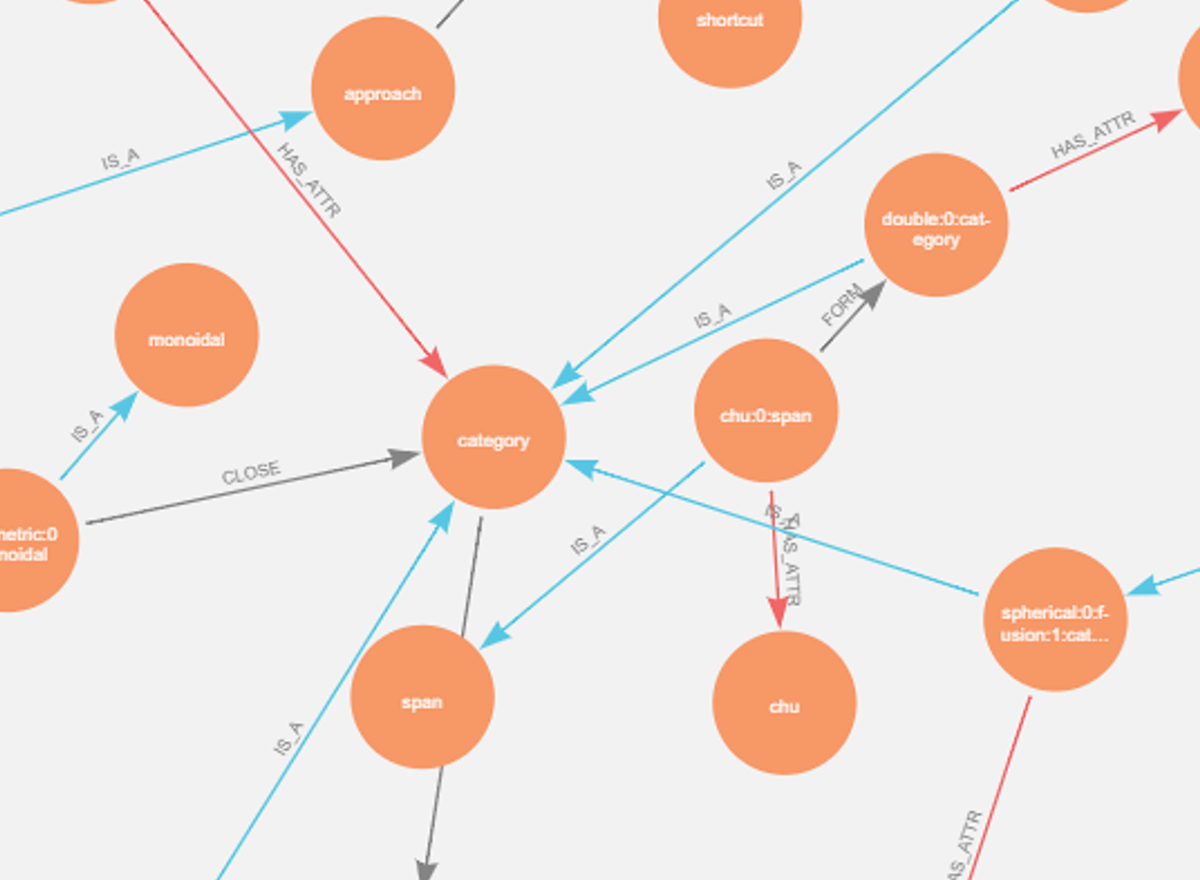
There is a common problem faced by scientists: determining if their work is similar to already published papers. I worked with a team of research scientists to help develop an automatically growing encyclopedia of mathematics concepts, which the software would use to draw similarities between an author’s work and existing contributions to the field.
Previous approaches used syntactic structures or deep learning to identify relationships between terms or keywords. I used a repository of existing papers in the field of category theory, which included a listing of author keywords for each respective paper, to construct a training dataset of keywords and relations. Then, I used this dataset to retrain a natural language model to perform better on mathematical texts. My approach resulted in an 87% improvement in the F1 score from 0.3 to 0.56. The model not only found more key terms, but it also discarded common extraneous filler words that are not terms (“and,” “the,” etc.). I represented the key data and relationships the model learned with a traversable knowledge graph, which you can see above. That graph spanned 4,000 terms and 6,000 relations which improved upon a previous paper submission.